| SalesPoint | Technischer Überblick | Einführendes Beispiel | Tutorial | Hooks | Javadoc | Download |
|
||||||||
|
Im folgenden wird die technische Realisierung des Frameworks "SalesPoint" beschrieben. Es sollen dadurch die Strukur und die Zusammenhänge des Frameworks verstanden und ein generelles Verständnis im Umgang mit den bereitgestellten Funktionen entwickelt werden. Es werden wichtige Begriffe und Konzepte erläutert, die im Framework umgesetzt werden. | ||||||||
|
Das Framework gliedert sich physisch in die Pakete
| ||||||||
|
Das Paket |
sale |
|||||||
|
In |
data |
|||||||
|
In dem Paket |
users |
|||||||
|
|
log |
|||||||
|
Von dem Paket |
util |
|||||||
|
Das folgende statische UML-Diagramm gibt einen Überblick über die wichtigsten Elemente des Frameworks. Es zeigt vor allem, wie die Klassen aus den unterschiedlichen Pakete untereinander zusammenarbeiten: 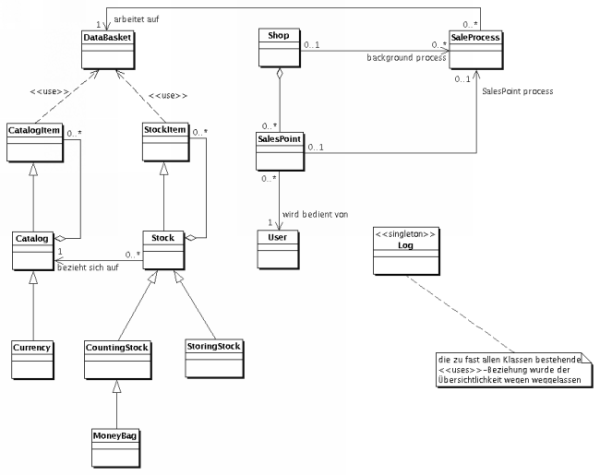 Abbildung 1.1: Übersichtsdiagramm | ||||||||
|
Das Framework zerfällt also in zwei große,
verhältnismäßig unabhängige Bereiche: die
Datenverwaltung ( |
Gliederung des Frameworks |
|||||||
|
||||||||
|
Beginnen wir mit dem Bereich der Applikationsverwaltung. Ein wichtiger
Begriff ist hier der des Ladens
( |
Laden und Verkaufsstand |
|||||||
|
Alle Interaktionen mit dem Laden finden im Rahmen von
Prozessen ( 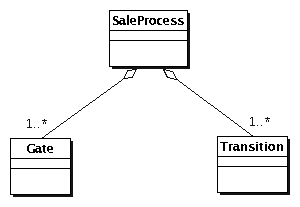 Abbildung 2.1: Prozesse bestehen aus Zuständen und Übergängen |
Prozesse |
|||||||
|
Die vom Framework vordefinierten Gates und die Reihenfolge, in der
von einem Gate zum nächsten gegangen wird, zeigt Abbildung
2.2.
Die jeweilige Implementierung schließt die Lücke
vom 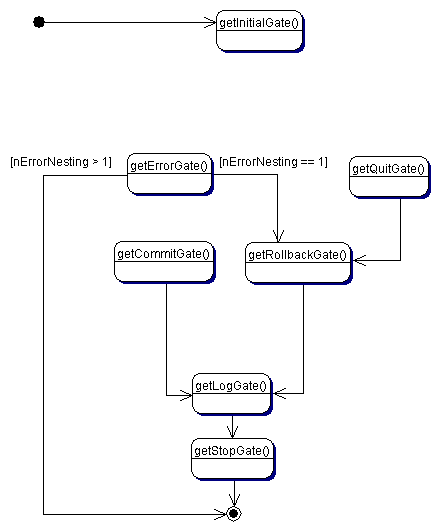 Abbildung 2.2: Zusammenhänge zwischen des einzelnen Gates |
Gates |
|||||||
|
Diese explizite Darstellung des Prozeßaufbaus im Objektmodell hat den zusätzlichen Vorteil, daß Prozesse von der Anwendung quasi "angefaßt" werden können. Das heißt, Prozesse können jederzeit in einem definierten Zustand (nämlich an einem Gate) unterbrochen und später an der selben Stelle wieder fortgesetzt werden. Befindet sich der Prozeß zum Zeitpunkt der Unterbrechung gerade in einer Transition, so wird er einfach am nächsten Gate unterbrochen. Damit dies aber überhaupt machbar ist, müssen ein paar Bedingungen eingehalten werden: Da das Unterbrechen von Prozessen nicht zur Systemblockade führen soll, fordert man, daß Transitionen verhältnismäßig kurz sind. Insbesondere dürfen sie keine "potentiell unendlich" andauernden Aktivitäten umfassen. "Potentiell unendlich" sind dabei alle Aktivitäten, deren Endtermin nicht vorherbestimmbar ist, zum Beispiel eine Benutzerkommunikation. Dabei könnte es vorkommen, daß der Benutzer einfach "vergißt", einen Knopf zu wählen, was dazu führen würde, daß die Transition nicht verlassen und damit der Prozeß nicht unterbrochen werden kann. Deshalb sind Benutzerkommunikation und ähnliche langandauernde Vorgänge nur an einem Gate erlaubt. Ein Prozeß darf sich beliebig lange an einem Gate aufhalten, muß aber sicherstellen, daß er zu jedem Zeitpunkt unterbrochen werden kann. Im Gegenzug wird einem Prozeß zugesichert, daß er nie während einer Transition unterbrochen wird. | ||||||||
|
Prozesse können auf verschiedene Arten ausgeführt werden.
Zum einen kann an jedem Verkaufsstand zu jedem Zeitpunkt
höchstens ein Prozeß ablaufen. Zum anderen können
Prozesse aber auch als Hintergrundprozesse wichtige Arbeit erledigen.
Um den Prozeß davon abzukoppeln, ob er gerade als
Hintergrundprozeß ( 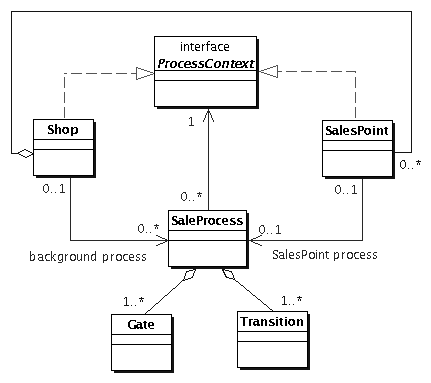 Abbildung 2.3: Prozesse können an Verkaufsständen und als Hintergrundprozesse laufen |
Prozeß-Umgebung |
|||||||
|
Wenn man mit dem Anwender kommunizieren will, so braucht man ein
gemeinsames Medium. Im Framework gibt es dafür die
Anzeige ( |
Anzeige |
|||||||
|
Auf einer Anzeige können Formulare
( |
Formulare und Menüs |
|||||||
|
Im Rahmen des Persistenzmanagements wurde ein weiterer Begriff, der
des Formular-Inhaltserzeugers
( |
FormSheetContentCreator |
|||||||
|
Formulare müssen gelegentlich mit ihrer Anzeige kommunizieren,
um sicherzustellen, daß sich Änderungen am Formular auch
sofort
auf die Anzeige auswirken. Wenn beispielsweise ein Formular einen
"Löschen"-Knopf hat, der ein, gerade
in einer Tabelle
ausgewähltes Element löscht, so soll dieser vielleicht
nicht selektierbar sein, wenn kein Eintrag in der Tabelle
ausgewählt ist. Die Anwendung würde also den Zustand des
Knopfes immer dann ändern, wenn sich die Auswahl in der Tabelle
ändert. Um den Zustand des Knopfes zu verändern, verwendet
die Anwendung eine entsprechende logische Operation, ohne sich um die
Umsetzung auf der Ebene von |
FomSheetContainer |
|||||||
|
Mit den Knöpfen in der Knopfleiste eines Formulars oder in einem
Menü werden Aktionen ( |
Aktionen |
|||||||
|
Jedes Formular oder Menü wird immer in einem gewissen Kontext dargestellt. Dieser besteht aus dem Laden in dem es dargestellt wird, gegebenenfalls dem Verkaufsstand an dem es dargestellt wird und/oder gegebenenfalls dem Prozeß, der es darstellt. Nur der Laden ist immer vorhanden. Aktionen, die mit Knöpfen eines Formulars oder Menüs verbunden sind, werden immer im Kontext dieses Formulars oder Menüs aufgerufen. Dies geschieht, in dem der entsprechenden Methode der Verkaufsstand und der Prozeß als Parameter übergeben werden. Der Laden ist ohnehin bekannt, da es nur einen pro Anwendung gibt. Die folgende Abbildung verdeutlicht diese Zusammenhänge noch einmal grafisch. 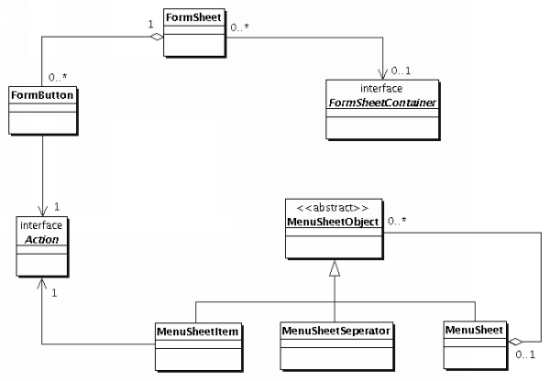 Abbildung 2.4: Formulare und Menüs verwenden Aktionen, um Benutzereingaben mit Programmreaktionen zu verknüpfen |
Menü-Kontext |
|||||||
|
Zum Abschluß dieses Abschnitts muß noch einmal der Laden erwähnt werden. Zusätzlich zu den hier geschilderten, eher konzeptionell begründeten Verantwortungen hat der Laden auch noch einige andere, eher technischer Natur. Auf abstraktester Ebene ließen sich diese etwa wie folgt motivieren: "Der Laden bildet das zentrale Element der Anwendung. Er bündelt sämtliche Aktivitäten und Verantwortungen." Das heißt, der Laden ist zentraler Ansprechpartner für alle Teile der Applikation. Er "kennt", entweder durch direkte Assoziation oder weil sie ein "Singleton" implementieren, sämtliche Elemente der Anwendung. Deshalb ist es nur natürlich, dem Laden auch die Verantwortung für das Persistenzmanagement (siehe Datenverwaltung) zuzuordnen. Auf "Knopfdruck", d.h. auf einen einfachen Methodenaufruf hin, kann der Laden den Zustand der gesamten Anwendung sichern, bzw. einen früher gespeicherten Zustand wiederherstellen. |
Der Laden als zentrale Verwaltungseinheit |
|||||||
|
||||||||
|
Ein weiterer, wichtiger und großer Bereich des Frameworks ist
die Datenverwaltung. Diese stellt für Verkaufsanwendungen
typische Datenstrukturen zur Verfügung. Außerdem stellt
sie Mechanismen bereit, die zur Implementation von
Transaktionseigenschaften wie Isolation und Atomizität verwendet
werden können. Es ist mit Hilfe des Frameworks ebenfalls
möglich den Zustand eines |
Datenverwaltung |
|||||||
|
Ein Geschäft stellt die angebotenen Waren oder Dienstleistungen
in Form eines oder mehrerer Kataloge
( |
Kataloge |
|||||||
|
Kataloge stellen Listen von potentiell verfügbaren Objekten dar.
Um tatsächlich verfügbare Objekte darzustellen,
benötigt man Bestände. Ein Bestand
( |
Bestände |
|||||||
|
Es gibt zwei grundlegende Typen von Beständen:
"zählende Bestände"
( |
Bestandstypen |
|||||||
|
Die Abbildung 3.1 stellt diese Zusammenhänge noch einmal grafisch dar. Sie zeigt außerdem zwei interessante zusätzliche Elemente: Kataloge bzw. Bestände sind selbst wieder Katalog- bzw. Bestandseinträge. Dadurch wird es möglich, auch mit geschachtelten Katalogen bzw. Beständen zu arbeiten. Diese können in manchen Anwendungen, die mit sehr komplexen Beständen arbeiten müssen, recht nützlich sein. Beispielsweise könnte eine Wechselstube, die Währungen zwischen denen sie wechseln kann, in einem Katalog anbieten. Die Währungen selbst sind wieder Kataloge, die die einzelnen Münzen und Banknoten beschreiben. In Analogie dazu gäbe es auch einen geschachtelten Bestand, der für jede Währung die Momentanbestände jedes einzelnen Schalters verwalten könnte. Werden geschachtelte Bestände verwendet, so müssen immer auch geschachtelte Kataloge benutzt werden. Der Katalog C, der von einem Bestand B referenziert wird, muß sich auf der gleichen Schachtelungsebene befinden wie B. Er muß außerdem im Katalog des Bestandes enthalten sein, der B enthält. Das heißt, das Konzept unterstützt die Strukturierung von Katalogen und Beständen, jedoch nur so lange wie die Strukturierung nicht in sich selbst informationstragend ist. |
Schachtelung von Katalogen und Beständen |
|||||||
|
Zweitens sieht man in dieser Abbildung, daß die gemeinsame
Eigenschaft, einen Namen zu haben, in dem Begriff des
Benennbaren ( |
Benennbare Objekte und Namenskontext |
|||||||
|
Die folgende Abbildung zeigt noch einmal die Zusammenhänge
zwischen 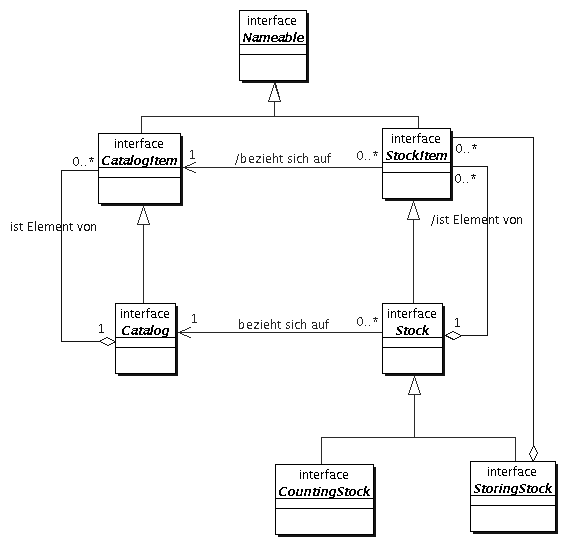 Abbildung 3.1: Kataloge und Bestände | ||||||||
|
Um Transaktionseigenschaften, wie Isolation und Atomizität, zu
implementieren, existiert der Datenkorb
( |
Datenkorb |
|||||||
|
Datenkörbe arbeiten eng mit den entsprechenden Containern zusammen, um ihre Funktion zu erfüllen. Wenn aus einem Bestand ein Element entnommen wird, so wird es zunächst in den Datenkorb eingeordnet. Solange das Element im Datenkorb ist, wird es vom Bestand als "vorläufig gelöscht" markiert. Erst wenn dem Datenkorb die Löschung des Elements bestätigt wurde (siehe unten), wird es endgültig aus dem Bestand gelöscht. Analog verhält es sich mit dem Hinzufügen von Elementen. Wird ein Element zum Bestand hinzugefügt, so wird es gleichzeitig in den entsprechenden Datenkorb eingefügt. Im Bestand wird es zunächst als "vorläufig hinzugefügt" markiert und steht anderen Nutzern zunächst nicht zur Verfügung. Erst wenn das Hinzufügen dem Datenkorb bestätigt wurde, wird das Element als "tatsächlich enthalten" markiert und wird für andere Nutzer sichtbar. Die Benutzung von Katalogen verläuft ganz analog. |
Elemente des Datenkorbs |
|||||||
|
Entsprechend der zwei möglichen Sichtweisen auf Datenkörbe gibt es auch zwei getrennte Untermengen der Datenkorbschnittstelle. Die eine bietet Funktionen, mit denen Transaktionseigenschaften implementiert werden können (Transaktionsschnittstelle), die andere bietet Funktionen, um den Inhalt des Datenkorbs zu inspizieren und auszuwerten (Inspektionsschnittstelle). |
Datenkorbschnittstelle |
|||||||
|
Die Transaktionsschnittstelle bietet verschiedene Variationen der Operationen commit und rollback. Diese werden verwendet, um Änderungen, die im Datenkorb registriert sind, zu bestätigen und endgültig festzuschreiben (commit) oder um sie rückgängig zu machen (rollback). Commit bzw. rollback können unbedingt, also für alle vom Datenkorb beschriebenen Aktionen, oder nur für eine Auswahl dieser Aktionen durchgeführt werden. Außerdem ist es möglich, Unterbereiche des Datenkorbs zu definieren, die ähnlich wie check points in Transaktionen verwendet werden können. |
Commit und Rollback |
|||||||
|
Die Inspektionsschnittstelle umfaßt Operationen zum Iterieren über den Inhalt des Datenkorbs sowie eine Funktion, um den Wert aller Elemente aufzusummieren, die einer bestimmten Bedingung genügen. Außerdem können Datenkörbe gespeichert werden, was bedeutet, daß auch der Zustand von Transaktionen gesichert werden kann, so daß diese später wieder fortgesetzt werden können. Faßt man die Aufgaben des Datenkorbs nochmals zusammen, so ergeben sich folgende Verantwortlichkeiten:
|
Datenverwaltung |
|||||||
|
Bestände, Kataloge und Datenkörbe können Ereignisse auslösen, wenn ihr Inhalt geändert wird. |
|
|||||||
|
||||||||
|
Das Framework umfaßt auch einen kleineren Bereich, der sich mit der Verwaltung von Benutzern beschäftigt. Hier sind die folgenden Begriffe wichtig. |
|
|||||||
|
Benutzer ( |
Benutzer und ihre Rechte |
|||||||
|
Benutzer werden von einer Benutzerverwaltung
( |
Benutzerverwaltung |
|||||||
|
||||||||
|
Ein kleiner Bereich des Frameworks beschäftigt sich mit dem Erstellen und Auswerten von Protokollen. |
|
|||||||
|
Protokolle ( 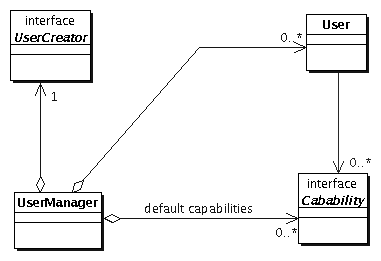 Abbildung 5.1: Benutzer haben Fähigkeiten und werden von Benutzermanagern verwaltet. |
Protokolleinträge |
|||||||
|
Auf Protokolle besteht nur Schreibzugriff, um Protokollströme zu
lesen und auszuwerten, benötigt man einen
Protokoll-Eingabestrom
( |
Filter |
|||||||
|
||||||||
|
Das Framework enthält bereits einige Standard-GUI-Komponenten.
Neben einfachen Formularen wie | ||||||||
|
Bei den meisten dieser Formulare werden zunächst die
entsprechenden |
Standard-Formulare |
|||||||
|
Ein wichtiges Element des Framework-GUI sind Tabellen. Dafür gibt es ein paar spezielle Komponenten, deren genauere Betrachtung sich an dieser Stelle lohnt. Die meisten im Rahmen des Frameworks darzustellenden Daten sind Listen von komplexen, aber gleichartigen Elementen. Um diese darzustellen, ist im Prinzip nur zu entscheiden, welche Attribute man darstellen möchte und in welcher Form. Man kann dann jedem darzustellenden Element eine Zeile und jedem darzustellenden Attribut eine Spalte einer Tabelle zuordnen. |
Komponenten von Tabellen |
|||||||
|
Für genau diese Art von Darstellung existieren im Framework die
folgenden Konzepte. In Anlehnung an das von Swing verwendete
MVC-Muster gibt es für jede Tabelle ein Modell. Die wesentlichen
Eigenschaften von Tabellen, die Listen von Datensätzen verwalten,
werden im abstrakten Tabellenmodel
( 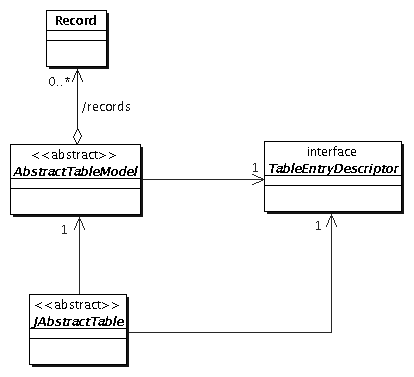 Abbildung 6.1: Tabellen beruhen auf einem Tabellenmodell, das eine Liste von Datensätzen mit Hilfe eines Datensatzschreibers auf Tabellenzeilen projiziert. |
Eigenschaften von Tabellen |
|||||||

| SalesPoint | Technischer Überblick | Einführendes Beispiel | Tutorial | Hooks | Javadoc | Download |
by kk15 and ch17